Quienes somos
eGrabber es líder en soluciones para edificio listas de prospección B2B personalizadas en casa.
Descripción general de eGrabber
eGrabber es el líder en soluciones para crear internamente listas de prospección B2B personalizadas.
Creamos herramientas que permiten a los usuarios crear listas de prospección B2B de forma más rápida y precisa que los expertos en SDR.
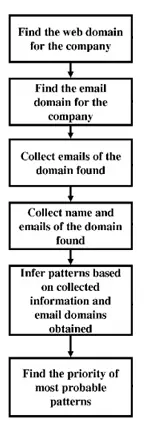
Nuestras herramientas son más rápidas y precisas porque hemos automatizado más de 50+ flujos de trabajo de creación de listas que suelen realizar los expertos en SDR, desarrollando algoritmos propios de análisis sintáctico y búsqueda web e integrando las mejores tecnologías de su clase.
Las listas que creamos son únicas y de alta conversión para cada cliente porque aprovechamos la inteligencia de las bases de datos internas del cliente (relaciones anteriores - clientes potenciales, clientes, usuarios), sus redes profesionales y fuentes web para crear listas.
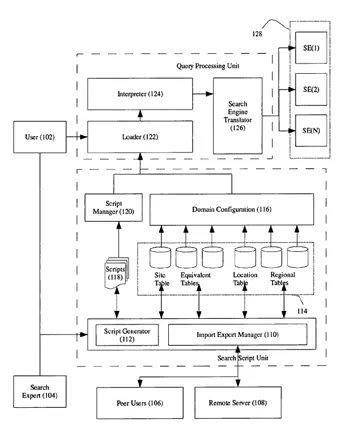
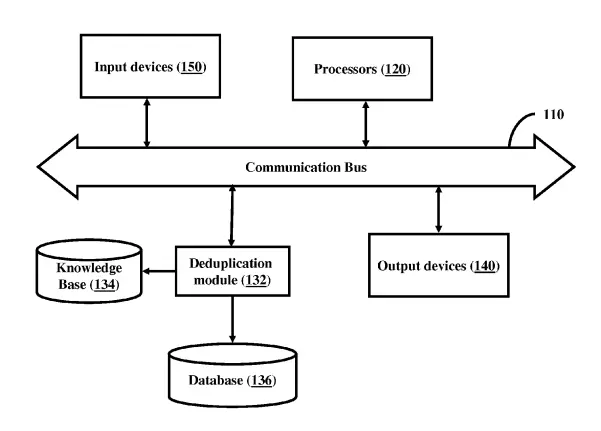
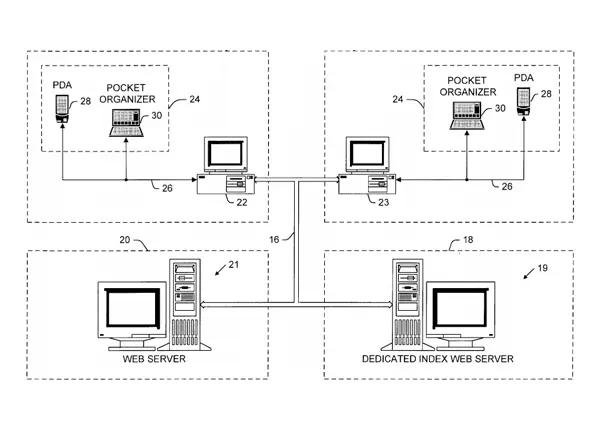
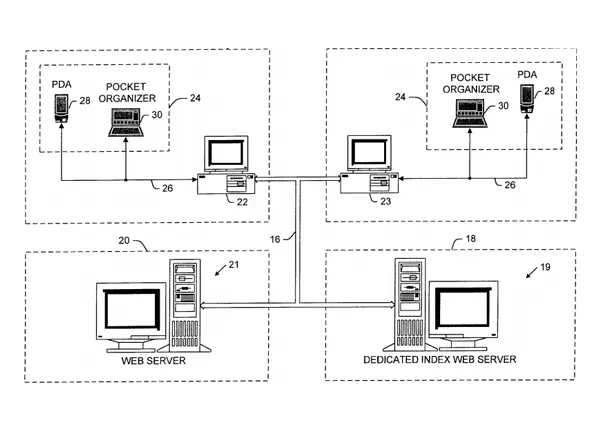
Patentes de EE.UU.
0
Las empresas emergentes y las PYMES adquirieron nuestras herramientas y las utilizaron pequeños equipos para el desarrollo de nuevos negocios.

1
Años de innovación Hemos sido pioneros en la generación de prospectos B2B durante más de dos décadas, perfeccionando constantemente los procesos para una investigación más simple.