Who we are
eGrabber is the leader in solutions for building custom B2B prospecting lists in-house.
eGrabber Overview
eGrabber is the leader in solutions to build custom B2B prospecting lists in-house.
We make tools that enable users to build B2B prospecting lists faster & more accurately than SDR Experts do.
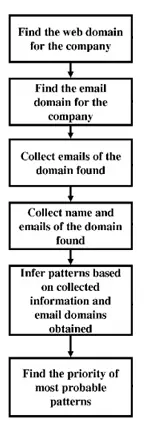
Our tools are faster & more accurate because we automated 50+ List Building work-flows commonly performed by SDR Experts, by developing proprietary parsing & web-research algorithms and integrating best-in-class technologies.
The lists we build are uniquely high-converting to each customer because we leverage intelligence from customer's in-house databases (past relationships - prospects, customers, users), their professional networks & web sources to build lists.
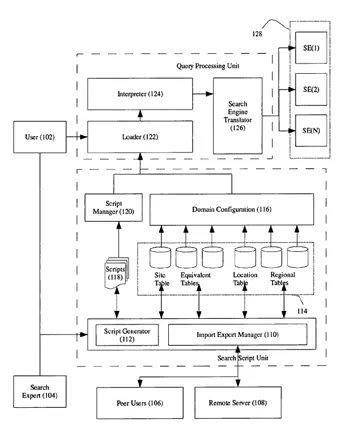
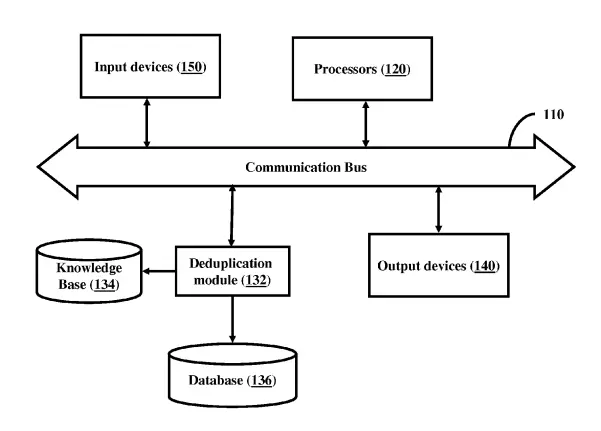
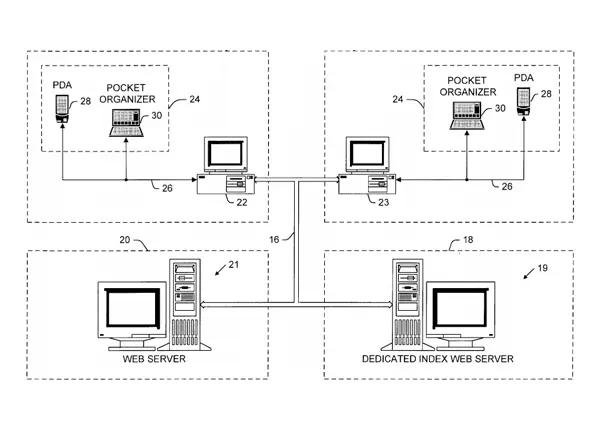
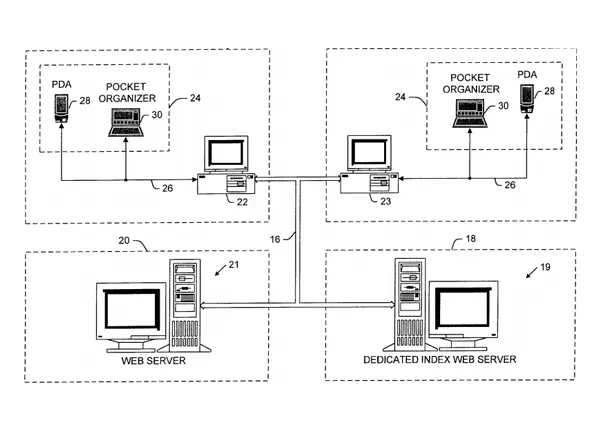
US Patents
0
Startups & SMBs purchased our tools and used by small teams for new business development

1
Years of Innovation We've pioneered B2B lead generation for over two decades, constantly refining processes for simpler research.